
Currently viewing the tag: "3ème génération"
![]() Une jeune start-up est née en mai 2012 : cette société issue du CNRS est porteuse d’une innovation dans le secteur du séquençage haut-débit. Enfin, une alternative française aux anglosaxons qui sont présents sur le marché depuis une dizaine d’année ! Maintenant… espérons que ce nouveau né n’arrive pas trop tard sur un marché animé par des fournisseurs de séquenceurs de 2ème génération (un marché mature) et d’autres fournissant des solutions de 3ème génération, riches de promesses.
Une jeune start-up est née en mai 2012 : cette société issue du CNRS est porteuse d’une innovation dans le secteur du séquençage haut-débit. Enfin, une alternative française aux anglosaxons qui sont présents sur le marché depuis une dizaine d’année ! Maintenant… espérons que ce nouveau né n’arrive pas trop tard sur un marché animé par des fournisseurs de séquenceurs de 2ème génération (un marché mature) et d’autres fournissant des solutions de 3ème génération, riches de promesses.
PicoSeq derrière ce nom emprunt d’humilité se cache une technologie de séquençage des plus ingénieuses : en effet, SIMDEQ™ (SIngle-molecule Magnetic DEtection and Quantification) la technologie de PicoSeq utilise une approche biophysique pour extraire des informations à partir de la séquence d’ADN ou d’ARN.
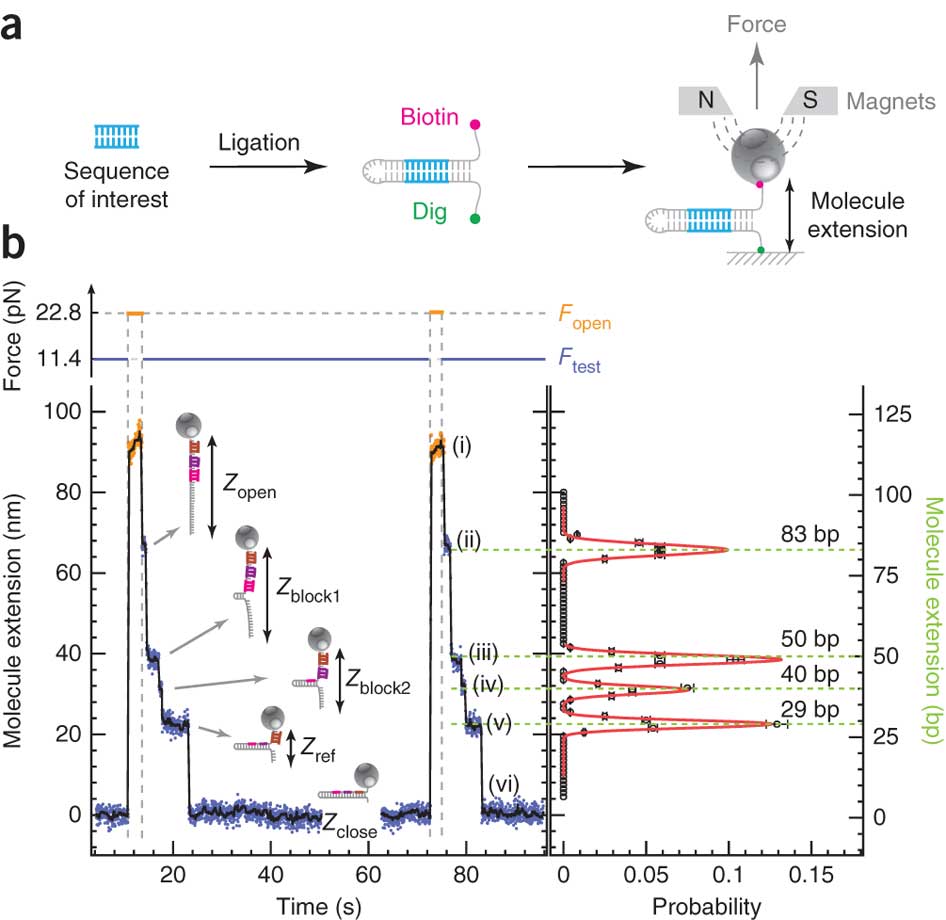
En s’appuyant sur cette représentation schématique tirée de Ding et al. (Nature Methods, 2012), on y voit un peu plus clair. Des fragments d’ADN ou d’ARN que l’on souhaite analyser servent de matrice pour la réalisation d’une librairie en «épingle à cheveux». Pour chaque épingle à cheveux, un côté d’un brin d’acide nucléique est attaché sur une surface solide plane et l’autre à une bille magnétique. En plaçant les billes dans un champ magnétique, modulant celui-ci de manière cyclique, les épingles à cheveux peuvent être auto-hybridées ou non (zip ou unzip). Ce processus peut être effectué des milliers de fois sans endommager les molécules constitutives de la librairie. La position de chaque bille est suivie à très haute précision permettant de voir ce processus d’ouverture et de fermeture en temps réel: nous avons donc là un signal brut permettant, en fonction de la force appliquée pour ouvrir totalement l’épingle à cheveu et des séquences d’oligonucléotides séquentiellement introduites dans le système de modifier la distance bille-support et de jouer sur le temps nécessaire où la force s’applique pour ouvrir l’épingle à cheveu…
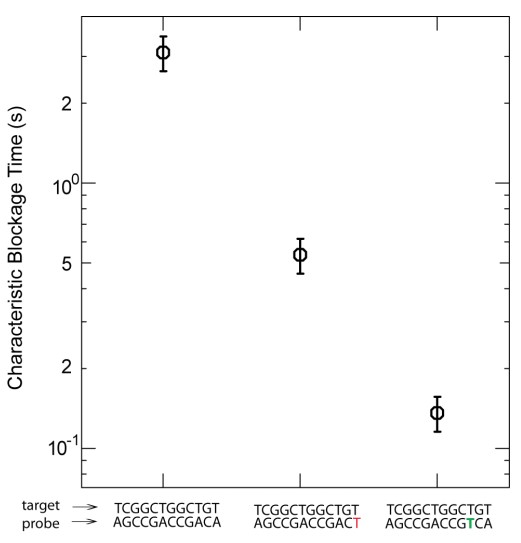
La figure ci-dessus (présente dans les données supplémentaires de l’article sus-cité) permet d’appréhender le potentiel de discrimination de la méthode… où le temps de blocage est fonction du nombre de mésappariements et de la position de ces mésappariements…
Finalement si l’aspect technique est intéressant puisqu’en rupture avec les méthodes proposées par PacBio certainement un peu moins avec le système proposé par Oxford Nanopore Technologies, si la perspective annoncée par PicoSeq est réellement séduisante: l’accès modifications épigénétiques de l’ADN, la question centrale est de savoir si le pas de la commercialisation (dans des conditions propices au succès) d’un tel outil, sera franchi.
Un article d’ Atlantico de septembre 2015, titré : les trois raisons pour lesquelles la France est incapable de rivaliser avec les géants américains de l’analyse ADN, est assez éclairant pour imaginer comment la concrétisation d’une preuve de concept peut être un chemin ubuescokafkaïen. Pour illustrer cela les propos de Gordon Hamilton, le directeur de la startup PicoSeq qui s’inquiète sur les entraves « typically french » peuvent faire office de témoignage. Ce dernier s’inquiète : « La qualité de la recherche scientifique (en France) est incroyable, l’une des meilleures » « le seul souci, c’est que l’on a beaucoup de difficultés ici à transformer ces recherches en vrai business » pour finir par citer en exemple les lenteurs administratives spécificités latines : « nous avons mis presque deux ans pour négocier les licences nécessaires aux brevets de Picoseq. Le même processus en Californie prend entre deux semaines et deux mois. Sur un marché aussi rapide que celui-ci, deux ans c’est très long. Tout change vite, c’est donc impossible pour nous d’être de sérieux concurrents de ces sociétés américaines qui ont toujours un temps d’avance ».

Le séquençage haut-débit voit cohabiter depuis quelques années deux générations de séquenceurs.
Au passage, une question Trivial Pursuit pour laquelle il faudra avoir un œil de caracal : quelqu’un sait quelle société a développé la première génération de séquenceurs haut-débit ? et quand ?
Les séquenceurs de deuxième génération se voient conditionnés sous forme de séquenceurs de paillasse (PGM de Ion Torrent, Miseq d’Illumina, GS-junior de Roche) permettant une démocratisation du séquençage, pendant que leurs grands frères pulvérisent la loi de Moore pour envisager un rendement (coût / Mb) toujours plus compétitif.
La large diffusion du séquençage de 3ème génération se laisse désirer laissant le champ libre à la génération précédente. Cet article vise à réaliser un court état des lieux du séquençage haut-débit de troisième génération : un futur plus ou moins lointain, de nouvelles applications potentielles.
La question : séquenceurs de 3ème génération, l’âge de raison, c’est pour quand ? est l’interrogation qui a hanté l’AGBT 2013 marqué par le silence d’Oxford Nanopore. Cette année 2013 fut marquée par le retrait d’Illumina du capital de la société britannique : « Oxford Nanopore Technologies Ltd a annoncé la vente d’une participation détenue par son concurrent américain Illumina Inc., une étape vers la fin d’une relation pleine de conflits dans la course au développement des séquenceurs haut-débit permettant de séquencer plus rapidement et pour moins cher. »
Avant de caractériser ce que sont, seront, pourront être les 3ème générations de séquenceurs, commençons par un rapide tour des caractéristiques générales de leurs prédécesseurs et principalement de ce qui constitue leurs points faibles :
– la phase d’amplification clonale (réalisée par PCR) est source de biais (doublons, erreurs de PCR)
– les problèmes liés au déphasage engendrant une chute de la qualité le long du read produit (ce qui bride la production de reads vraiment longs)
-des reads courts (de moins d’une centaine à environ 800 bases – vous l’aurez noté ce point est en partie une conséquence du précédent)
-des machines et des consommables onéreux
– des temps de run longs
Ainsi l’objectif principal des séquenceurs de 3ème génération est de palier les défauts de leurs aînés en produisant des reads plus longs, plus vite pour moins cher. Les séquenceurs de 2ème génération, quels que soient leurs modes de détection (mesure de fluorescence, mesure de pH) sont trop peu sensibles pour envisager la détection d’une simple molécule, d’un simple nucléotide : nécessairement la librairie doit être amplifiée, ce qui provoque des biais, des temps de préparation relativement longs et l’usage de consommables qui impacte le coût final de séquençage… assez rapidement la qualité chute plus vos reads s’allongent ce qui oblige à brider les tailles de reads que ces technologies sont capables de délivrer. En outre, travaillant sur une matrice qui est une copie de votre librairie initiale, l’information portée par les bases méthylées est perdue (ceci oblige à ajouter une phase de traitement au bisulfite qui peut être hasardeuse)
Actuellement l’une des seules technologies de 3ème génération réellement utilisée est celle de Pacific Biosciences (les hipsters disent « PacBio »). La firme, fondée en 2004, a lancé en 2010, son premier séquenceur de troisième génération le Pacbio RS basé sur une technique de séquençage SMRT (Single Molecule Real Time sequencing.) Aujourd’hui la société Roche qui n’a pu absorber Illumina lors de son OPA, a investi 75 millions de USD, le 25 septembre 2013, pour co-développer des kits diagnostiques in vitro exploitant la technologie de PacBio.
La technologie de PacBio est aujourd’hui exploitée pour réaliser du séquençage de novo de petits génomes :

Avec ces 200 à 300 Mb délivrés par SMRT-cell, séquencer des organismes eucaryotes supérieurs demande un investissement important, malgré tout, cette technologie délivrant des reads de plusieurs milliers de bases, permet d’envisager une diminution du nombre de contigs obtenus par les seules stratégies reads-courts / gros débit.
Face à la technologie proposée par PacBio, d’autres technologies essaient d’émerger pour arriver à occuper le marché du séquençage de 3ème génération :
– La combinaison détection optique et multipore est une voie envisagée pour le séquençage de 3ème génération avec le travail mené par NobleGen biosciences.
– L’imagerie directe de l’ADN
Le microscope électronique offre une résolution possible jusqu’à 100 pm, de sorte que les biomolécules et les structures microscopiques tels que des virus, des ribosomes, des protéines, des lipides, des petites molécules et des atomes même simples peuvent être observés. Bien que l’ADN est visible lorsqu’on l’observe avec un microscope électronique, la résolution de l’image obtenue n’est pas suffisamment élevée pour permettre le déchiffrement de la séquence, c’est à dire, le séquençage de l’ADN. Cependant, lors du marquage différentiel des bases de l’ADN avec des atomes lourds ou des métaux, un tel séquençage devient possible.

– Le séquençage à l’aide de transistor (Transistor-mediated DNA sequencing– une technologie développée par IBM)

Dans le système conceptualisé par IBM, l’ADN est contraint de passer par le pore à cause de la tension électrique subie, la vitesse de passage de la molécule à séquencer est maîtrisée à l’aide de contacts métalliques à l’intérieur du nanopore. La lecture des bases serait réalisée lors du passage de l’ADN simple brin au travers du pore (ça rappelle quelque chose…)
– Et Oxford Nanopore dans tout cela ? Si la société anglaise a annoncé la vente de la participation d’Illumina, elle a marqué l’année 2013 par son silence assourdissant. Passé l’oxymore, en cette fin d’année, coup de poker ou réel lancement, Oxford Nanopore propose un programme d’accès à sa technologie Minion où pour 1000 USD, il est possible de postuler à l’achat des clés USB de séquençage.
La stratégie d’Oxford Nanopore est basée, en partie, sur la possible démocratisation du séquençage de 3ème génération, elle s’oppose à celle de PacBio qui mise sur son arrivée précoce sur le secteur du séquençage haut-débit : décentralisation contre l’inverse. En clair, l’investissement d’un PacBio est tel que l’outil est réservé à des centres, des prestataires de services pouvant assumer cet investissement, ce qui oblige à centraliser les échantillons pour les séquencer, contre les produits (encore en développement) d’Oxford Nanopore dont la promesse est : le séquençage pour tous (ou presque).
PacBio revendique sa participation à un projet qui consiste à doubler la quantité de génomes bactériens « terminés » (actuellement de 2384) en quelques mois.

En cliquant ci-dessus sur la représentation graphique qui illustre la différence de plasticité de génome entre le génome d’une Bordetella pertussis (l’agent pathogène responsable de la coqueluche) et celui d’Escherichia coli, un poster vous apparaîtra. Ce dernier reprend les caractéristiques de l’utilisation de la technologie de PacBio à des fins d’assemblage de novo de génomes bactériens par une stratégie non-hybride (seuls des reads de PacBio sont utilisés). Les résultats sont assez bluffants, la longueur des reads de PacBio permet un assemblage complet (au prix de plusieurs SMRT cells tout de même !), de génomes bactériens « difficiles » tel que celui de Bordetella pertussis connu pour posséder un GC % relativement élevé (environ 65 %) ainsi que de nombreux éléments transposables. Les génomes possédant de nombreux éléments répétés posent de grandes difficultés d’assemblage, c’est un des arguments qui permet à PacBio de positionner sa technologie actuellement… en quelques mois les stratégies hybrides (reads courts générés par des séquenceurs de 2ème génération) ont laissé place aux stratégies non-hybrides où le séquençage PacBio se suffit à lui-même.
Le terme « Nouvelle génération de séquençage à haut-débit » ( ou « Next generation sequencing » ) regroupe l’ensemble des technologies ou plateformes de séquençage développées depuis 2005 par quelques sociétés de biotechnologies.
L’objectif de cet article est de proposer de manière synthétique, un tour d’horizon des différents principes et caractéristiques de ces nouveaux outils et ainsi fournir quelques orientations et solutions techniques en réponses à des questions biologiques.
La position actuelle dans laquelle nous nous trouvons, entre la commercialisation de certains séquenceurs et ceux en cours de développement, est caractéristique d’une période charnière dissociant les technologies à haut débit dites de 2ème génération qui requièrent une étape d’amplification des molécules d’ADN en amont du décodage, de celles dites de 3ème génération permettant le décryptage direct d’une seule molécule d’ADN. Cette dernière catégorie fera à elle seule l’objet d’un prochain article.
Le marché des séquenceurs de 2éme génération est couvert par 3 grand groupes que sont Roche, Illumina et Life Technologies ayant respectivement proposés de manière successive, leur première plateforme à savoir le 454, le Genome Analyser et enfin le SOLiD. Depuis, le marché s’est étoffé proposant un panel de technologies au principe et caractéristiques propres telles qu’elles sont mentionnées ci dessous. A noter que parmi ce panel, le PGM, Ion torrent est le seul a connaitre une évolution constante en terme de capacités de séquençage (10Mb – reads de 100b – Juin 2011 / 100Mb – reads de 100b – Sept 2011 / 100Mb – reads 200b – Nov 2011 / 1Gb – Jan 2012 )

Chaque plateforme possède ses avantages et inconvénients et nombreuses sont celles configurées pour répondre à de nombreuses approches « omics », dans certaines limites. Il s’agira de faire un choix technologique selon les champs d’applications souhaités.
De manière générale, le type d’organisme étudié prédéterminera la technologie à employer. La notion de profondeur est récurrente à chaque application et dans l’objectif d’un reséquençage, le choix de la plateforme peut être identifié, de manière simplifiée, sur la base d’un calcul rapide ( P = N / L où P: Profondeur, N: Nombre des nucléotides totaux des reads, L: Taille du génome étudié).
Concernant les séquenceurs de 2ème génération, le séquençage de novo est une application mentionnée chez de nombreux fournisseurs (cf le tableau ci-dessous). Toutefois, l’association de deux technologies générant à la fois des reads longs (type 454, Roche) et une profondeur conséquente (type GAIIx, Illumina) palliant aux problèmes liés aux homopolymères et erreurs de séquençage, est préconisée (Au cours de l’article à venir sur les séquenceurs de 3ème génération, nous aborderons les plateformes davantage configurées pour cette application).
Ce paramètre de profondeur sera également à prendre en considération pour les champs d’applications incluant la notion d’analyse quantitative (RNAseq, ChIPseq, …). Si la profondeur permet d’atténuer les erreurs de séquençage, il reste néanmoins préférable de s’orienter vers des technologies à Q30 minimum (1 erreur sur 1000) pour la détection de SNPs.

Selon les technologies évoquées ci-dessus, les caractéristiques et champs d’applications ont évolués. Aussi, je vous propose de retrouver l’ensemble de ces informations actualisées en cliquant sur ce lien.
L’ensemble des informations sont détaillées dans l’article mentionné ci-dessous:

Qui sommes nous?
Christophe Audebert [@]
 En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
Renaud Blervaque [@]
 Biologiste moléculaire, chargé d'études génomiques.
Biologiste moléculaire, chargé d'études génomiques.
Gaël Even [@]
 Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.
Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.

