
Posts by: Gaël Even
Cette article fait suite à notre post sur l’intervention du professeur Arnaud Fontanet de l’Institut Pasteur sur le Coronavirus COVID-19.
Dans sa présentation, le professeur Fontanet renvoie vers trois sites web qui permettent de mieux comprendre le coronavirus.
Chacun dans leur contexte (observation/simulation/étude), ces sites montre la rapidité avec laquelle les chercheurs peuvent développer des outils bioinformatiques de data visualisation pertinents pour la communauté.
Ceci étant bien sur rendu possible à partir du moment où le partage de données épidémiologiques, génétiques, génomiques (…) est effectué.
Pour observer :
Coronavirus COVID-19 Global Cases by Johns Hopkins CSSE
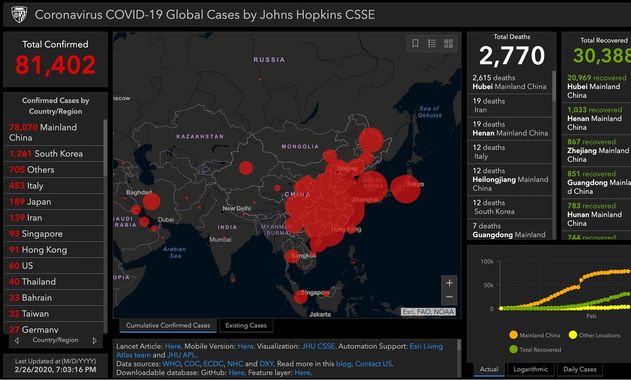
L’université John Hopkins maintient une carte avec des données en temps réel sur le nombre de patients diagnostiqués avec le nouveau coronavirus, le nombre de patients décédés et le nombre de patients guéris. Ces chiffres sont basés sur des informations provenant, entre autres, de l’Organisation mondiale de la santé (OMS) et du Centre européen de prévention et de contrôle des maladies (ECDC). Il peut y avoir de légères différences dans les chiffres réels .
Pour connaître les derniers chiffres confirmés, nous renvoyons aux sites web de l’OMS et de l’ECDC
Github – entrepôt de données : https://github.com/CSSEGISandData/COVID-19
Pour anticiper :
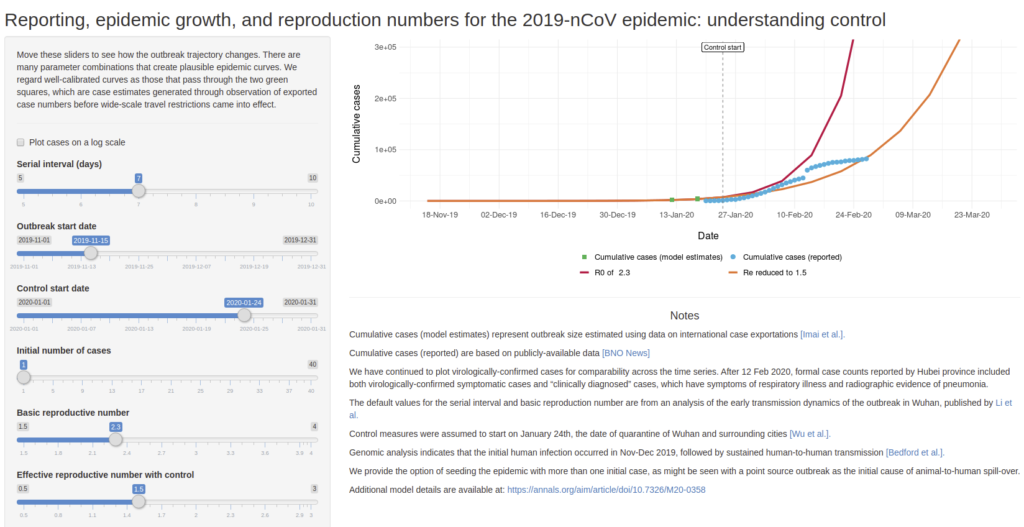
Permet de simuler des scénario de croissance de l’épidémie de COVID-19 en faisant varier quelques paramètres comme :
Serial interval (days) : nombre de jours avant de tomber malade
Outbreak start date : date de début de la maladie
Control start date : date de mise en place de controle (quarantaine, confinement,…)
Initial number of cases : nombre de cas initialement détectés
Basic reproductive number : nombre de personne à leur tour infecté par un malade si aucun contrôle n’est mis en place
Effective reproductive number with control : nombre de personnes à leur tour infecté par un malade si un contrôle est mis en place
Développé par Ashleigh Tuite et David Fisman, Dalla Lana School of Public Health, Université de Toronto
Pour étudier :
Genomic epidemiology of novel coronavirus (HCoV-19)
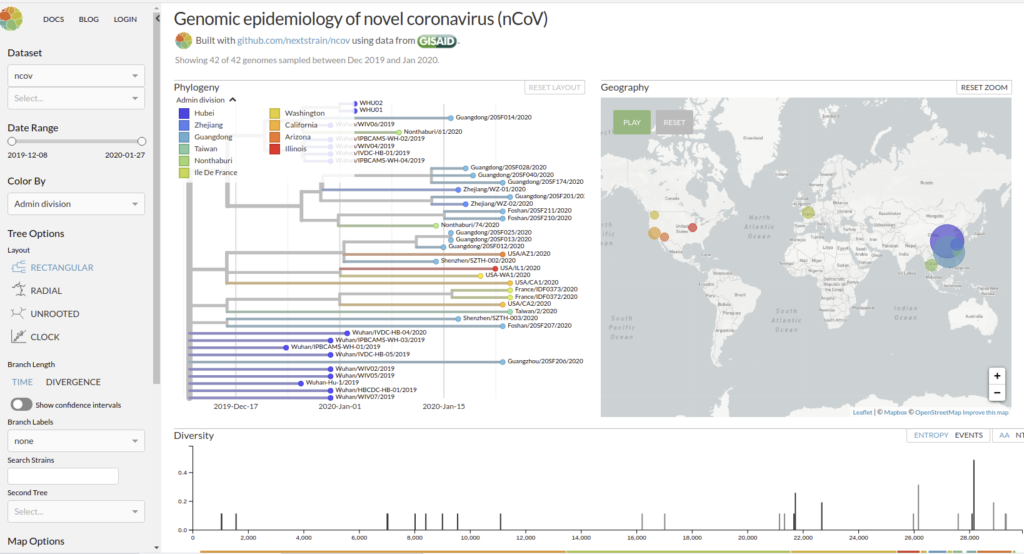
Nextstrain est un projet à open-source visant à exploiter le potentiel scientifique et de santé publique des données sur le génome des agents pathogènes. ils fournissent une vue continuellement mise à jour des données accessibles au public ainsi que de puissants outils d’analyse et de visualisation à l’usage de la communauté. L’objectif est d’aider à la compréhension épidémiologique et d’améliorer la réponse aux épidémies.
Il permet de visualiser les divergences phylogeniques entre les différentes génomes de COVDIR-19 séquencés à ce jour [ 20/02/2020 ]
En savoir plus : Hadfield et al., Nextstrain: real-time tracking of pathogen evolution, Bioinformatics (2018)
Github de l’application : https://github.com/nextstrain/ncov
Des explications précises et instructives sur l’état actuel (au 20 février 2020) des connaissances concernant l’épidémie provoquée par ce nouveau Coronavirus (COVID-19) – Durée : 35Min
Le professeur Arnaud Fontanet revient en détail sur l’histoire de ce virus, de la découverte des premiers cas, à l’enquête sur son mode de transmission jusqu’à son séquençage extrêmement rapide.
Il donne également beaucoup d’informations sur la durée d’incubation, la contagion, les symptômes associés, les mesures sanitaires et le travail des épidémiologistes et des chercheurs pour endiguer la propagation.
Les conséquences économiques ainsi qu’un parallèle pas inintéressant avec la grippe saisonnière permettront, pour certains, de mettre en perspective cette épidémie par rapport à notre monde actuel…
Cette intervention fait partie du MOOC de l’Institut Pasteur « Virus émergents et réémergents ».
Selon une étude : La consommation (modérée) de vin rouge liée à une meilleure santé intestinale…
Une étude du King’s College de Londres tend à montrer que les personnes qui boivent du vin rouge présenteraient une plus grande diversité de microbiote intestinal (un signe de santé intestinale) que les buveurs de vin non rouge.
Dans un article publié le 28 août dans la revue Gastroenterology, une équipe de chercheurs du Department of Twin Research & Genetic Epidemiology au King’s College de Londres a étudié l’effet de la bière, du cidre, du vin rouge, du vin blanc et des spiritueux sur le microbiote intestinal et sur la santé qui en découle chez un groupe de 916 jumelles britanniques. Pourquoi des jumelles? Pour que le fond génétique soit identique, donc la différence de microbiote intestinal entres les jumelles sera en grande partie dû à l’environnement.
Ils ont constaté que le microbiote intestinal des buveurs de vin rouge était plus diversifié que celui des buveurs de vin non rouge. Ceci n’a pas été observé avec la consommation de vin blanc, de bière ou de spiritueux.
La première auteure de l’étude, Caroline Le Roy, du King’s College de Londres, a déclaré : « Bien que nous connaissions depuis longtemps les bienfaits inexpliqués du vin rouge sur la santé cardiaque, cette étude montre qu’une consommation modérée de vin rouge est associée à une plus grande diversité et à un microbiote intestinal plus sain qui explique en partie ses effets bénéfiques sur la santé. »
Le microbiome est la collection de micro-organismes dans un environnement et joue un rôle important dans la santé humaine. Un déséquilibre entre les « bons » microbes et les « mauvais » microbes dans l’intestin peut entraîner des effets néfastes sur la santé, comme un affaiblissement du système immunitaire, un gain de poids ou un taux de cholestérol élevé.
Le microbiote intestinal d’une personne ayant un nombre plus élevé d’espèces bactériennes différentes peut-être considéré comme un marqueur de la santé intestinale.
L’équipe a observé que le microbiote intestinal des consommateurs de vin rouge contenait un plus grand nombre d’espèces bactériennes différentes que celui des non-consommateurs. Ce résultat a également été observé dans trois cohortes différentes au Royaume-Uni, aux États-Unis et aux Pays-Bas. Les auteurs ont tenu compte de facteurs tels que l’âge, le poids, le régime alimentaire régulier et le statut socio-économique des participants et ont continué à voir l’association.
Les auteurs croient que la raison principale de cette association est due aux nombreux polyphénols présents dans le vin rouge. Les polyphénols sont des produits chimiques de défense naturellement présents dans de nombreux fruits et légumes. Ils ont de nombreuses propriétés bénéfiques (y compris des antioxydants) et agissent principalement comme un carburant pour les microbes présents dans notre système.
L’auteur principal, le professeur Tim Spector du King’s College de Londres, a déclaré : « Il s’agit de l’une des plus importantes études jamais réalisées sur les effets du vin rouge sur l’intestin de près de trois mille personnes dans trois pays différents et elle montre que les niveaux élevés de polyphénols dans la peau du raisin pourraient être responsables d’une grande partie des bienfaits controversés pour la santé lorsqu’ils sont utilisés avec modération. »
« Bien que nous ayons observé une association entre la consommation de vin rouge et la diversité du microbiote intestinal, boire du vin rouge rarement, comme une fois toutes les deux semaines, semble suffisant pour observer un effet. Si vous devez choisir une boisson alcoolisée aujourd’hui, c’est le vin rouge qu’il faut choisir, car il semble exercer un effet bénéfique sur vous et sur vos microbes intestinaux, ce qui peut aussi aider à réduire le poids et le risque de maladies cardiaques. Cependant, il est toujours conseillé de consommer de l’alcool avec modération, vous n’avez pas à boire du vin rouge, et vous n’avez pas à commencer à en boire si vous ne buvez pas », a ajouté le Dr Le Roy.
Effectivement, comme dans toute étude, corrélation n’est pas raison! Ainsi et même si la catégorie socio-économique est prise en compte dans l’étude, il pourrait exister d’autres facteurs, non mesurés dans cette étude, qui expliqueraient en partie la bonne santé microbienne des individus. Rappelons que ça n’est pas l’alcool qui est associé avec une meilleure santé intestinale mais d’autres composants du vin rouge (l’hypothèse étant que ce sont les polyphénols), que l’on trouvera aisément dans d’autres aliments (fruits, légumes, noix, cacao…) .
Emplacement de la publication originale :
https://www.sciencedirect.com/science/article/abs/pii/S0016508519412444
L’abus d’alcool est dangereux pour la santé, consommez avec modération
Voici OMICtools, une initiative française visant à aider les chercheurs dans la recherche d’outils appropriés pour leurs besoins en analyses de données ‘omiques’
https://omictools.com/
Le constat est simple : les avancées dans les domaines du séquençage, des puces à ADN, de la spectrométrie de masses ont révolutionné la recherche biologique et biomédicale. Cette explosion de données générées engendre de nouvelles problématiques et entraîne une demande toujours plus forte en analyse. Par voie de conséquence, la communauté bioinformatique/biostatistique est extrêmement dynamique en ce qui concerne la création de nouveaux logiciels/méthodes pour l’analyse de données « omiques ». L’émergence de standard dans ce contexte est plutôt complexe au vue du nombre de solutions existantes pour répondre à des problématiques précises.
OMICtools propose une base de données « curée » en accès libre de plus de 4000 solutions d’analyses. Dès le départ, depuis notre problématique d’analyse et grâce à une arborescence à trois niveaux, nous sommes guidés pour arriver à une liste robuste d’outils répondant aux besoins.
OMICtools ne se contente pas de décrire précisément le rôle de chaque solution analytique, il liste également les bases de données associés ainsi que des liens très intéressants vers la littérature tel que des protocoles analytiques ou des comparaisons d’outils. Le fait de lier outils, bases de données et littérature est une des forces de l’outil.
Pour illustrer la navigation, si nous nous plaçons dans le cadre d’une analyse RNA-seq si nous nous posons la question simpliste (mais néanmoins essentielle) : comment dois-je analyser mes données? De (très) nombreuses questions sous-jacentes surgissent en même temps que des solutions : quel outil pour aligner ou assembler? deNovo ou sur référence? S’intéresse t-on à l’épissage alternatif? à la détection de variants? à la quantification des mRNA? quelle méthode de quantification? quelle méthode de normalisation? quelle mesure d’expression différentielle? quelles analyses fonctionnelles en aval?
Pour chaque question, il existe des solutions logicielles, plus ou moins efficaces, plus ou moins fonctionnelles, mais également des comparatifs sous forme de publications qui peuvent aider aux choix. OMICtools propose donc de référencer ces solutions par problématiques en essayant de séparer le bon grain de l’ivraie (OMICtools est vérifié et mis à jour par ces auteurs).
OMICtools permet à un novice dans un domaine de rapidement visualiser les workflows d’analyse et les enjeux analytiques grâce à des schéma associés en illustration de chaque problématique (ex : schéma d’analyse metagénomiques…).
Le projet Plume (Promouvoir les Logiciels Utiles Maîtrisés et Économiques dans la communauté de l’Enseignement Supérieur et de la Recherche – www.projet-plume.org) est une initiative assez similaire initiée en 2007 et référençant plus de 1200 solutions logicielles. Le projet Plume est plus généraliste, les fiches sont bien plus détaillées et sont en français (ce qui peut-être un inconvénient pour une portée plus internationale). Le projet Plume fonctionne toutefois en mode dégradé faute de moyen…
La publication associée à OMICtools est disponible ici : http://database.oxfordjournals.org/content/2014/bau069.long
Après quelques mois d’absence suite à un problème de mise à jour, Biorigami est de retour. Nous nous excusons pour cette longue période d’inactivité.

- Coursera propose des cours interactif en ligne
Lancé en avril 2012, Coursera est une entreprise qui propose un accès gratuit à un ensemble de cours en ligne. Rien de nouveau par rapport aux nombreux MOOC (pour « massive open online course ») de plus en plus présents sur la toile? Dans cet article nous égrènerons les principales caractéristiques de Coursera : ses atouts, en quoi il se démarque du cours en ligne classique et pourquoi il pourrait constituer une petite révolution dans le monde éducatif .
– La plupart des MOOC sont très centrés autour de l’informatique (on peut le comprendre), des sciences mathématiques et de l’ingénierie. Coursera propose un panel de cours très variés, allant de la médecine à la poésie en passant par l’économie et l’histoire, sans oublier la biologie et la bioinformatique. On trouve même des cours de guitare en ligne!
– Coursera a conclu un partenariat avec des dizaines d’universités (dont de très prestigieuses) à travers le monde, offrant ainsi des cours de haute qualité dans différentes langues: fin 2012 Coursera annonce 680 000 inscrits provenant de 42 pays.
– Pour les instructeurs, Coursera est un catalyseur de propagation du savoir, certains cours dépassant les 100 000 étudiants, beaucoup plus que les 400 étudiants qu’un professeur peut espérer instruire chaque année dans son université. Un professeur de l’université de Stanford a ainsi calculé que son cours Coursera de 100 000 étudiants revenait à distiller des cours à une classe pendant 250 ans!
– Les cours sont fixés dans le temps, renouvelés, interactifs avec l’insertion de questionnaires au milieu des présentations, des exercices à rendre et à corriger, des forums pour partager. L’apprentissage est clairement maximisé si on se donne la peine de suivre assidument les cours. Coursera s’appuie sur des principes pédagogiques simples :
- Les questionnaires et exercices permettent d’ancrer le savoir
- Le partage et les corrections des exercices par ses pairs donnent une vision différente sur son travail et la façon dont l’étudiant a lui-même assimilé (se mettre à la place du correcteur en quelque sorte)
- L’organisation en classes: la présence d’un forum permet de partager son expérience et ses conseils avec ses pairs , ce qui est plus motivant.
– Pour les étudiants /autodidactes, c’ est une aubaine : participer à des cours réservés d’habitude à une élite et tout cela gratuitement, vive le e-learning!
Pour l’instant le plan d’affaire semble un peu flou. Pour plus de détails vous pouvez consulter la page Wikipedia dédiée à Coursera. Des certificats de participation authentifiés sont déjà délivrés (de l’ordre de 30 à 60$ par cours) pour permettre à l’e-étudiant de valoriser les compétences acquises. Coursera pourrait aussi vendre votre profil à des entreprises de recrutement (avec l’accord des étudiants). A terme des frais de scolarité pourraient être également appliqués.
Les nouveaux MOOC tels que Coursera, Udacity (MOOC plutôt centré sur les disciplines scientifiques) ou edX ( association à but non-lucratif ) sont-ils en train de révolutionner notre façon d’apprendre? Il nous faudra attendre quelques années avant de mesurer l’impact de cette propagation à grande échelle de l’apprentissage. Va-t-on assister à une véritable explosion du nombre d’autodidactes aussi compétents que de nouveaux diplômés? Ou cette manne de savoir va-t-elle rester marginale et utilisée par une élite déjà formée par le système universitaire « classique » et avide de nouvelles connaissances?
Pour finir, voici les principaux cours liés aux biotechnologies actuellement sur Coursera :



A plus long terme, vous retrouverez également un cours de l’université de Melbourne sur l’épigénétique qui commencera au 1er juillet et un cours d’introduction à la bioinformatique par l’université de San Diego d’ici la fin d’année 2013.
La liste complète des cours autour des sciences de la vie est disponible à cette adresse : https://www.coursera.org/courses?orderby=upcoming&cats=biology
Dans la forme, cette vidéo (en anglais) se veut humoristique mais le fond est assez sérieux puisqu’il montre ce qui ne devrait pas arriver quand un scientifique effectue une demande (courtoise) de partage de données : Un enchainement d’échanges souvent à la limite de l’absurde reflet d’une situation malheureusement assez commune dans le domaine de la science.
Auteurs : Karen Hanson, Alisa Surkis and Karen Yacobucci

La double hélice d'adn capturée
La nouvelle provient de l’Institut Italien de Technologie de Gènes : l’équipe du professeur Enzo di Fabricio (responsable du département de Nanostructures) a réussi à capturer l’image d’une molécule d’ADN à l’aide d’un microscope électronique en transmission et d’un support en silicone hydrophobe.
L’équipe a développé un support ( formé de colonnes dites « nanopiliers » ) extrêmement hydrophobe, provoquant ainsi l’évaporation, pour ne laisser visibles que des brins d’ADN tendus. L’équipe a également percé de petits puits dans le fond du support « nanopilier » (voir la photographie du support ci-dessous), à travers lequel ils font pénétrer des faisceaux d’électrons pour obtenir leur capture en haute résolution.
Cette image est générée en utilisant la technologie de microscopie TEM pour « transmission electron microscopy » qui repose sur le principe de transmission d’un faisceau d’électrons à travers un support très mince. Plus précisément une image est formée à partir des d’interactions entres les électrons et le support; le résultat peut ensuite être imprimé sur un film photographique ou capturé via un détecteur numérique. Cette technologie offre une grande résolution indispensable pour visualiser un brin d’adn.

Zoom sur le support permettant de visualiser l'adn
Sur l’image en en-tête on repère bien la forme hélicoïdale de la double-hélice d’ADN.
Outre l’aspect « inédit » de cette technique, elle ouvre également des perspectives intéressantes: on pourrait être ainsi en mesure d’observer (réellement) la façon dont une molécule d’ADN interagit avec diverses biomolécules.
Pour en savoir plus : l’article « Direct Imaging of DNA Fibers: The Visage of Double Helix » publié dans Nanoletters (American Chemical Society) en Novembre 2012
 Lors d’articles précédents nous vous avions présenté le logiciel de Workflow Galaxy, qui permet d’analyser et de visualiser toutes sortes de données biologiques à partir d’une interface simple d’utilisation.
Lors d’articles précédents nous vous avions présenté le logiciel de Workflow Galaxy, qui permet d’analyser et de visualiser toutes sortes de données biologiques à partir d’une interface simple d’utilisation.
Galaxy est en fait une brique d’une collection d’outils dédiés à l’analyse et au stockage de données biologiques : GMOD ( Generic Model Organism Database )
Le lundi 14 mai a été l’occasion pour nous d’assister à une conférence sur l’utilisation de certains des outils GMOD, dont voici les principaux enseignements :
> Le projet GMOD a pour objectif de fournir à l’utilisateur biologiste un ensemble d’outils interconnectés, libre de droit (open-source), générique (pour tous types de données biologiques) et facile d’utilisation (à travers des services Web principalement)
> Les outils GMOD sont développés (et donc installés) par des bioinformaticiens pour une utilisation par des biologistes.
> Certains outils sont indispensables à GMOD, pour la manipulation de données génomiques, c’est le cas des outils Chado et Gbrowse qui sont respectivement les squelettes pour la manipulation et pour la visualisation des données biologiques.
Le schéma ci-dessous décrit les modules et interactions présentés lors de cette journée thématique :

GMOD - Modules et interactions présentés le 14 juin
En résumé :
> Chado est un schéma générique de base de données relationnelles pour le stockage de tous types de données biologiques.
Description détaillée : GMOD-CHADO
> GBrowse est un outil de visualisation de données biologiques très puissant et certainement l’outil le plus populaire de la suite GMOD
Description détaillée : GMOD-GBROWSE
> Biomart est un outil de recherches avancées (ou requêtes complexes) pour la base de donnée relationnelle Chado
> Apollo est un module pour la correction manuelle d’annotation structurelle
Description détaillée : GMOD-APOLLO
> Tripal est une interface web développée en PHP pour interrogation de Chado
Pour aller plus loin : Détails techniques sur l’utilisation des outils GMOD :

Environnement informatique : CHADO fonctionne par défaut avec Postgres-Sql. Pour l'interfaçage avec Tripal, la solution étant développée avec PHP, il est nécessaire d'installer un serveur Web Apache. Gbrowse peut s'utiliser à partir de l’interface Tripal mais également en "stand-alone". Afin d'accélérer la visualisation des données il est vivement recommandé d'utiliser les adapteurs Bio::DB::*, soit en relais entre Chado et Gbrowse (présentés dans cet article), soit en dupliquant les informations dans les deux bases de données (la visualisation ne se connecte qu'à Bio::DB sans passer par CHADO). Intuitivement, nous privilégions la première solution qui n’entraîne pas de duplication.
Pour conclure, GMOD propose un ensemble de modules pour la standardisation des processus bioinformatique : stockage et manipulation de données biologiques, visualisation et analyses avancées (assemblage, annotation…).
L’utilisation de tels outils (open-source) va dans le bon sens pour le partage scientifique et la standardisation des processus utilisés lors de l’analyse bioinformatique. Cela n’était pas le but de la conférence à laquelle nous avons assistée mais il serait également intéressant de connaître les conditions pour intégrer ces propres outils bioinformatiques en tant que brique GMOD.
GMOD est donc intéressant si :
> vous souhaitez stocker et gérer vos données biologiques
> vous cherchez des solutions d’analyses bioinformatiques déjà développées et robustes
Les biologistes sont les utilisateurs des outils GMOD, en revanche l’installation, l’administration et la formation des utilisateurs ne peuvent échapper à l’intervention, au moins ponctuelle, d’un bioinformaticien.
Si vous projetez d’utiliser ces outils, nous vous conseillons donc dans un premier temps, de regrouper l’ensemble des acteurs, installateurs comme utilisateurs de GMOD, afin de présenter les solutions offertes par l’outil et déterminer les besoins et objectifs pour votre propre utilisation.
Le réseau régional d’ingénieurs en bioinformatique de Lille et le PPF bioinformatique organisent lundi 14 Mai 2012 une conférence sur l’utilisation des outils GMOD (Generic Model Organism Database). Cette conférence se déroulera de 13h30 à 17h30 dans l’amphithéâtre de l’Institut de Biologie de Lille.
« Le projet GMOD a pour objectif de fournir une série d’outils génériques, clé en main, pour gérer et visualiser différents types de données biologiques. »
Deux interventions sont prévues :
Olivier Arnaiz du CGM Centre de Génétique Moléculaire (UPR 3404 Gif-sur-Yvette) introduira GMOD tout en se focalisant plus particulierement sur deux outils : Chado et Gbrowse. Chado est un schéma de base de données relationnelles qui permet d’intégrer des données « omiques » (génomiques, transcriptomices, séquençages…), tandis que GBrowse est un outil permettant de visualiser des annotations sur un génome.
Joelle Amselem de l’INRA – URGI (BIOGER Versailles) présentera un outil d’annotation développé à l’URGI à partir de modules GMOD. Deux exemples concrets d’utilisation seront développés.
Pour en savoir plus, vous pouvez télécharger le programme ici.
Si vous souhaitez des informations sur GMOD, je vous invite à consulter la présentation de GMOD.
Qui sommes nous?
Christophe Audebert [@]
 En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
Renaud Blervaque [@]
 Biologiste moléculaire, chargé d'études génomiques.
Biologiste moléculaire, chargé d'études génomiques.
Gaël Even [@]
 Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.
Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.

