
From the monthly archives: juin 2016
Malgré, le tirage d’oreilles de la FDA (la Food and Drug Administration), les consommateurs de génomique récréative ne se sont pas réellement détournés de 23andMe, société dans laquelle Google a injecté 4,0 millions d’USD. La société de Anne Wojcicki l’ex-épouse du cofondateur de Google, Sergey Brin, n’a pas vu une perte significative de clientèle et, au contraire, a continué de recruter de nouveaux clients… pour franchir le cap du 1.000.000 durant l’année 2016.

L’implication de Google dans la société s’essoufflant (un divorce prononcé entre les fondateurs respectifs des deux sociétés, en 2015), 23andMe a cherché à transformer sa base de données de profils génomiques en profits financiers directs. Ainsi, plus d’une dizaine de sociétés ont négocié un accès à ces informations (Genentech, Pfizer, etc.). Ces informations semblent aujourd’hui constituer le vrai « business model » de 23andMe.
Si cette monétisation était complètement prévisible, il faut avouer que l’impact ou plutôt le non impact de la prise de position de la FDA atténue grandement ce que l’on avait pu annoncer au sein de l’article : 23andMe au point mort.

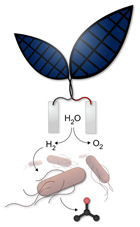
Les cellules photovoltaïques ont un potentiel considérable pour satisfaire les besoins futurs en énergie renouvelable, cependant des méthodes efficaces et évolutives de stockage de l’électricité intermittente qu’elles produisent, sont aujourd’hui attendues pour la mise en œuvre, à grande échelle, de l’énergie solaire. Un stockage de cette énergie solaire pourrait passer par la case carburant. Le travail, présenté dans PNAS de février 2015 (Efficient solar-to-fuels production from a hybrid microbial–water-splitting catalyst system), rapporte le développement d’un système bioélectrochimique évolutif, intégré dans lequel la bactérie Ralstonia eutropha est utilisée pour convertir efficacement le CO2, avec l’hydrogène et l’oxygène produits à partir de dissociation de l’eau, en biomasse et alcools (cf. schéma ci-contre). Les systèmes photosynthétiques artificiels peuvent stocker l’énergie solaire et réduire chimiquement le CO2. Le système de fractionnement-biosynthétique hybride est basé sur un système de catalyseur inorganique, relativement abondant sur Terre (nécessairement sinon écologiquement ce ne serait pas terrible, avouons le…), biocompatible pour séparer l’eau en hydrogène et oxygène à des tensions basses. Lorsqu’elle est cultivée en contact avec ces catalyseurs, Ralstonia eutropha consomme le H2 produit pour synthétiser de la biomasse et des carburants voire d’autres produits chimiques, à partir de faible concentration de CO2 – sous entendu à des concentrations voisines de celles présentes dans l’air. Ce système évolutif a une efficacité énergétique de réduction de CO2 d’ ~ 50% lors de la production de la biomasse bactérienne et d’alcools. Ce dispositif hybride couplé à des systèmes photovoltaïques existants donnerait une efficacité énergétique de réduction des émissions de CO2 d’environ 10%, supérieure à celle des systèmes photosynthétiques naturels ! Nous en conviendrons la bactérie utilisée ici est génétiquement modifiée afin d’orienter son métabolisme vers une voie anabolique d’intérêt.

Ces travaux ouvrent la voie vers la « photosynthèse de synthèse ». Dans cette configuration intégrée, les rendements du solaire à la biomasse vont jusqu’à 3,2% du maximum thermodynamique pour dépasser celle de la plupart des plantes terrestres. En outre, l’ingénierie de R. eutropha a permis la production d’isopropanol jusqu’à 216 mg/L, le plus haut rendement jamais rapporté (> 300 %). Ce travail démontre que les catalyseurs d’origine biotique et abiotique peuvent être interfacés, intégrés… pour permettre à partir de l’énergie solaire, du CO2 et de quelques bactéries de développer des systèmes efficaces stockant une énergie intermittente sous forme de molécules organiques (le biomimétisme est la vraie tendance du moment).
Dans cette première version (celle du PNAS) l’électrode utilisée en nickel-molybdène-zinc s’est avérée toxique pour les bactéries qui voyaient leur ADN attaqué… dans cette version améliorée publiée dans Science (3 juin 2016) , l’électrode toxique a été changée par une autre composée de cobalt-phosphore… Selon Daniel Nocera, le promoteur de l’étude : « Cela nous a permis d’abaisser la tension conduisant à une augmentation spectaculaire de l’efficacité. »
, l’électrode toxique a été changée par une autre composée de cobalt-phosphore… Selon Daniel Nocera, le promoteur de l’étude : « Cela nous a permis d’abaisser la tension conduisant à une augmentation spectaculaire de l’efficacité. »
Nocera et ses collègues ont également été en mesure d’élargir la gamme de produits q’un tel système est capable de synthétiser pour y inclure l’isobutanol (un solvant) et l’isopentane (utilisé dans des boucle fermée pour actionner des turbines), ainsi que le PHB (un précurseur de bioplastiques). La conception chimique du nouveau catalyseur permet également une certaine « auto-régénération, » ce qui signifie que l’électrode ne sera pas lessivée au fur et à mesure de son activité.
 A moitié scientifique et à moitié homme d’affaire, Craig Venter qui n’a pas très bon goût concernant les couvertures de ses livres essaie de mettre la main sur les données de plusieurs centaines de milliers à plusieurs millions de génomes (séquences totales ou profils génétiques). Mais que l’on se rassure c’est pour le bien de l’humanité ou au moins de la transhumanité !
A moitié scientifique et à moitié homme d’affaire, Craig Venter qui n’a pas très bon goût concernant les couvertures de ses livres essaie de mettre la main sur les données de plusieurs centaines de milliers à plusieurs millions de génomes (séquences totales ou profils génétiques). Mais que l’on se rassure c’est pour le bien de l’humanité ou au moins de la transhumanité !
Depuis 2005, les technologies de séquençage n’ont cessé d’être plus rapides et moins chères. En 2014, plus de 225.000 génomes humains étaient déjà séquencés grâce à plusieurs initiatives dont le fameux « 100 000 Genomes Project » britannique lancé en 2013. Début 2014 Illumina lançait une campagne de publicité mettant en scène le HiSeqX Ten, le premier séquenceur permettant d’atteindre la promesse d’un coût de séquençage humain à 1000 $. Cette année AstraZeneca annonçait sa collaboration avec le Human Longevity Institute de Craig Venter permettant à ce dernier un accès aux génomes ou profils génomiques de 2 000 000 de personnes d’ici 2020. En utilisant la seule séquence d’ADN, Venter dit que son entreprise peut maintenant prédire la taille, le poids, la couleur des yeux et la couleur des cheveux d’une personne, et produire une image approximative de son visage. Une grande partie de ces « détails » est dissimulé dans les variations rares, dit Venter, dont le propre génome a été mis à disposition dans les bases de données publiques depuis plus d’une décennie. Soit dit en passant, même ce promoteur d’un certain transhumanisme regrette son geste : « Si je devais conseiller un jeune Craig Venter », je dirais, réfléchissez bien avant que vous veniez déverser votre génome sur Internet« …
Quelques questions centrales demeurent et l’une d’elle consiste à envisager que le génome d’une personne n’est pas du ressort de sa seule propriété… en effet, rendre disponible son génome revient à rendre disponible une partie des informations de ces enfants et des enfants de ceux-ci etc. Effectivement, les promoteurs de la génomique à large échelle envisagent de dépasser les problématique de l’héritabilité cachée (à ce sujet, lire l’excellent article de Bertrand Jordan dans M/S : Le déclin de l’empire des GWAS). Voici un extrait très pertinent qui explicite ce problème : « Les identifications réalisées dans le cadre des études GWAS sont certes scientifiquement valables et utiles pour la compréhension du mécanisme pathogène (donc porteuses d’espoirs thérapeutiques), mais, rendant compte de moins d’un dixième des héritabilités constatées, elles passent visiblement à côté d’un phénomène important… Comment résoudre ce paradoxe ? Il faut pour cela revenir sur ce qu’examinent réellement les GWAS. Elles se limitent aux Snip, faisant (pour le moment du moins) l’impasse sur les copy number variations (CNV), ces délétions, duplications ou inversions dont on a découvert récemment plusieurs centaines de milliers dans notre génome. Et même pour les Snip, elles ne donnent pas une image complète des variations génétiques entre individus. Par la force des choses, les 500 000 Snip représentés sur les puces d’Affymetrix ou d’Illumina (et qui ont préalablement été étudiés par le consortium HapMap) correspondent à des poymorphismes assez facilement repérables dans un échantillon de population : la règle adoptée a été de ne retenir que les Snip pour lesquels la fréquence de l’allèle mineur est au moins égale à 5 %. Cet usage était nécessaire pour limiter les difficultés dans le positionnement des Snip lors de l’établissement des cartes d’haplotypes ; mais il a pour conséquences que les GWAS n’examinent que les variants fréquents… Selon une hypothèse largement répandue, les maladies multigéniques fréquentes (diabète, hypertension, schizophrénie…) seraient dues à la conjonction de plusieurs allèles eux aussi fréquents : c’est la règle « common disease, common variant » souvent évoquée depuis une dizaine d’années. Les résultats de la centaine d’études d’association pangénomiques pratiquées à ce jour indiquent que cette hypothèse est très probablement fausse : les variants communs ne rendant compte que d’une faible partie de l’héritabilité, le reste est vraisemblablement dû à des variants rares (ponctuels ou non) dont ces études ne tiennent pas compte puisque les puces utilisées ne les voient pas. »
Ainsi, pour franchir ce cap, une solution simple est envisagée : le changement de résolution avec pour credo le passage de profils génomiques (quelques millions de SNPs) à l’intégralité du génome… et après l’épigénome et en même temps le métagénome. Si ces sciences bâties sur une technologie en pleine révolution permettent l’accès à un patrimoine humain universel (l’information génomique quasi exhaustive), si ces sciences renouvellent sans cesse leurs promesses -il faut des fonds et donc convaincre les pouvoirs publics pour acheter la technologie américaine qui permet d’accomplir ces sciences- hypothéquer le patrimoine humain ou pire le privatiser pourrait être une erreur dramatique dont on a du mal à mesurer l’étendue des conséquences.
![]() Une jeune start-up est née en mai 2012 : cette société issue du CNRS est porteuse d’une innovation dans le secteur du séquençage haut-débit. Enfin, une alternative française aux anglosaxons qui sont présents sur le marché depuis une dizaine d’année ! Maintenant… espérons que ce nouveau né n’arrive pas trop tard sur un marché animé par des fournisseurs de séquenceurs de 2ème génération (un marché mature) et d’autres fournissant des solutions de 3ème génération, riches de promesses.
Une jeune start-up est née en mai 2012 : cette société issue du CNRS est porteuse d’une innovation dans le secteur du séquençage haut-débit. Enfin, une alternative française aux anglosaxons qui sont présents sur le marché depuis une dizaine d’année ! Maintenant… espérons que ce nouveau né n’arrive pas trop tard sur un marché animé par des fournisseurs de séquenceurs de 2ème génération (un marché mature) et d’autres fournissant des solutions de 3ème génération, riches de promesses.
PicoSeq derrière ce nom emprunt d’humilité se cache une technologie de séquençage des plus ingénieuses : en effet, SIMDEQ™ (SIngle-molecule Magnetic DEtection and Quantification) la technologie de PicoSeq utilise une approche biophysique pour extraire des informations à partir de la séquence d’ADN ou d’ARN.
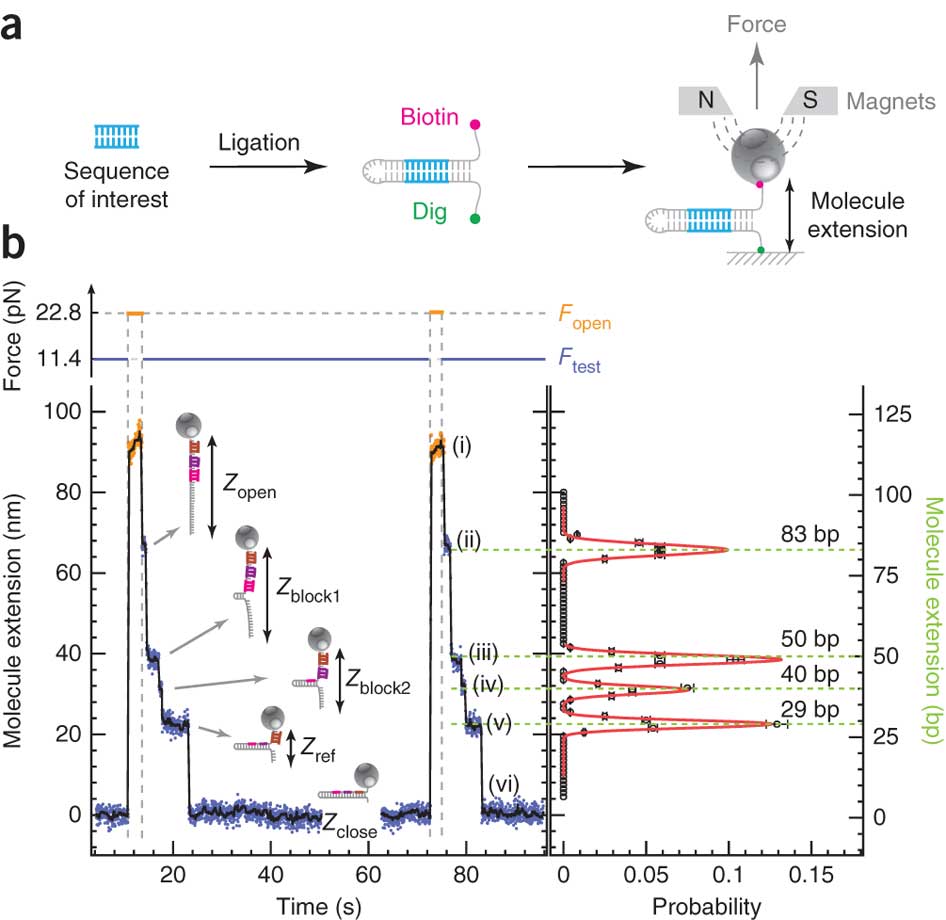
En s’appuyant sur cette représentation schématique tirée de Ding et al. (Nature Methods, 2012), on y voit un peu plus clair. Des fragments d’ADN ou d’ARN que l’on souhaite analyser servent de matrice pour la réalisation d’une librairie en «épingle à cheveux». Pour chaque épingle à cheveux, un côté d’un brin d’acide nucléique est attaché sur une surface solide plane et l’autre à une bille magnétique. En plaçant les billes dans un champ magnétique, modulant celui-ci de manière cyclique, les épingles à cheveux peuvent être auto-hybridées ou non (zip ou unzip). Ce processus peut être effectué des milliers de fois sans endommager les molécules constitutives de la librairie. La position de chaque bille est suivie à très haute précision permettant de voir ce processus d’ouverture et de fermeture en temps réel: nous avons donc là un signal brut permettant, en fonction de la force appliquée pour ouvrir totalement l’épingle à cheveu et des séquences d’oligonucléotides séquentiellement introduites dans le système de modifier la distance bille-support et de jouer sur le temps nécessaire où la force s’applique pour ouvrir l’épingle à cheveu…
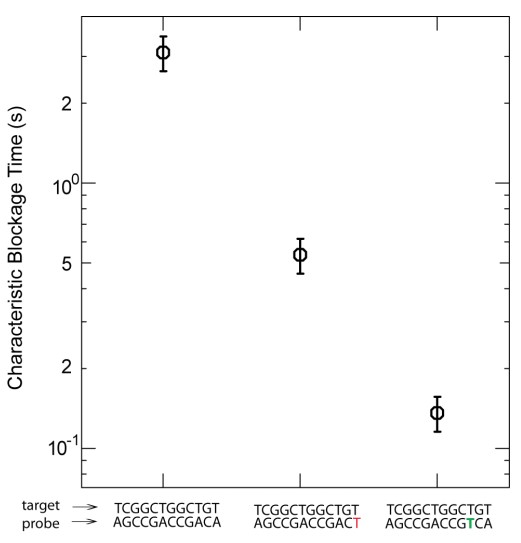
La figure ci-dessus (présente dans les données supplémentaires de l’article sus-cité) permet d’appréhender le potentiel de discrimination de la méthode… où le temps de blocage est fonction du nombre de mésappariements et de la position de ces mésappariements…
Finalement si l’aspect technique est intéressant puisqu’en rupture avec les méthodes proposées par PacBio certainement un peu moins avec le système proposé par Oxford Nanopore Technologies, si la perspective annoncée par PicoSeq est réellement séduisante: l’accès modifications épigénétiques de l’ADN, la question centrale est de savoir si le pas de la commercialisation (dans des conditions propices au succès) d’un tel outil, sera franchi.
Un article d’ Atlantico de septembre 2015, titré : les trois raisons pour lesquelles la France est incapable de rivaliser avec les géants américains de l’analyse ADN, est assez éclairant pour imaginer comment la concrétisation d’une preuve de concept peut être un chemin ubuescokafkaïen. Pour illustrer cela les propos de Gordon Hamilton, le directeur de la startup PicoSeq qui s’inquiète sur les entraves « typically french » peuvent faire office de témoignage. Ce dernier s’inquiète : « La qualité de la recherche scientifique (en France) est incroyable, l’une des meilleures » « le seul souci, c’est que l’on a beaucoup de difficultés ici à transformer ces recherches en vrai business » pour finir par citer en exemple les lenteurs administratives spécificités latines : « nous avons mis presque deux ans pour négocier les licences nécessaires aux brevets de Picoseq. Le même processus en Californie prend entre deux semaines et deux mois. Sur un marché aussi rapide que celui-ci, deux ans c’est très long. Tout change vite, c’est donc impossible pour nous d’être de sérieux concurrents de ces sociétés américaines qui ont toujours un temps d’avance ».
Qui sommes nous?
Christophe Audebert [@]
 En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
Renaud Blervaque [@]
 Biologiste moléculaire, chargé d'études génomiques.
Biologiste moléculaire, chargé d'études génomiques.
Gaël Even [@]
 Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.
Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.

