
 Le fait de simuler des données de séquençage est une approche de plus en plus populaire pour qui aime à jouer avec les solutions analytiques de séquençage haut-débit. Il va sans trop de développement nécessaire que l’une des caractéristiques de ces jeux de données synthétiques est leur totale maîtrise (organisme(s) à l’origine de la séquence, taux d’erreurs, d’insertion, de délétion, % de séquences contaminantes etc...). Le tout permettant relativement aisément d’exploiter des métriques telles que la F-measure qui peut se définir comme, un métrique qui combine la moyenne harmonique du rappel (sensibilité) et de la précision (spécificité), ceci donnant
Le fait de simuler des données de séquençage est une approche de plus en plus populaire pour qui aime à jouer avec les solutions analytiques de séquençage haut-débit. Il va sans trop de développement nécessaire que l’une des caractéristiques de ces jeux de données synthétiques est leur totale maîtrise (organisme(s) à l’origine de la séquence, taux d’erreurs, d’insertion, de délétion, % de séquences contaminantes etc...). Le tout permettant relativement aisément d’exploiter des métriques telles que la F-measure qui peut se définir comme, un métrique qui combine la moyenne harmonique du rappel (sensibilité) et de la précision (spécificité), ceci donnant
A des fins de comparaisons de différentes méthodes: plus une F-measure est élevée et proche de 1, plus votre méthode de mapping de reads, par exemple, sera jugée performante (encore faut il que le temps d’exécution soit jugé acceptable). Plus trivialement, ces reads synthétiques permettent de prendre en main les ressources, les logiciels et autres contingences nécessaires à une analyse post-séquençage liée à une technologie que vous souhaiteriez maîtriser. Des technologies pour lesquelles, trouver des données contrôlées, conformes à vos attentes, est plutôt difficile à exhumer. Certes la banque SRA du NCBI héberge une grande quantité de données produites sur un large spectre de technologies mais principalement dans un contexte de recherche donc difficilement contrôlable. Seules les séquences relatives à des run test, à partir de l’ADN d’organismes pris comme calibrateurs, telle que la coli DH10B permettent d’appréhender ces données en réalisant l’hypothèse que l’organisme séquencé correspond parfaitement à la séquence de référence disponible (est ce systématiquement le cas ? nous pouvons largement en douter…).
Quoi qu’il en soit un nombre croissant d’outils est disponible. Ces outils plus ou moins paramétrables permettent de simuler des données d’à peu près n’importe quel séquenceur… La publication de Merly Escalona et al. dans le Nature Reviews (Genetics) de juin 2016 vous est disponible en cliquant sur l’image « A comparison of tools for the simulation of genomic next-generation sequencing data » en tête de cette article. Cette publication est, à ce jour, le plus complet tour d’horizon de cette problématique liée aux simulateurs de données de séquençage… problématique qui n’est pas le seul apanage des bio-informaticiens ou bio-analystes…
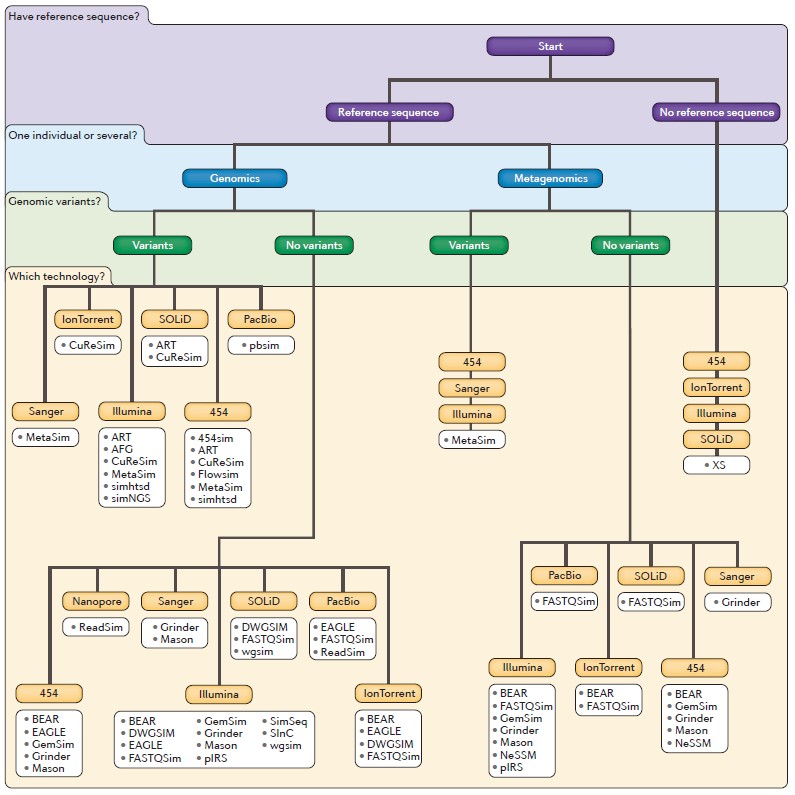
Ce schéma reprend les caractéristiques de la vingtaine de simulateurs abordés dans la publication Escalona et al.
c.audebert
Partager cet article



Qui sommes nous?
Christophe Audebert [@]
 En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
Renaud Blervaque [@]
 Biologiste moléculaire, chargé d'études génomiques.
Biologiste moléculaire, chargé d'études génomiques.
Gaël Even [@]
 Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.
Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.

